本記事は、2026年5⽉時点の内容です。
マーケティングユニット AI・データチャプターの枝です。
現在の業務では Snowflake 環境の構築および運用を担当し、これまでオンプレのデータ分析基盤で実施していたマーケティング施策のクラウド化支援に携わっています。
本記事では、Snowflake で標準で提供されている機能の一つである Streamlit を活用し、データ処理業務の運用効率化を実現する方法の一例についてご紹介します!
はじめに
データ分析基盤として Snowflake を導入したものの、その多機能さゆえに十分な活用が進まず、日々の運用業務が手運用による属人的な対応となってしまうケースも少なくありません。
クエリを直接実行してデータの状態を確認したり個別にログをトレースしたりといった運用は、担当者のスキルや経験に依存しやすく、異常が発生した際にリカバリが遅れたり、影響範囲の調査に時間を要したりするリスクがあります。
こうしたリスクを回避するため、Snowflake の標準機能である Streamlit を活用し、運用業務をアプリケーションとして標準化します。これにより、状況確認やリカバリ対応を簡単に実施することができる仕組みを目指します。
想定読者
Snowflake 上での高度な知識を前提とせず、初学者の方でも読み進められる内容として、以下のような方を想定しています。
- Snowflake の導入から日が浅い方
- Snowflake の基本的な SQL 操作はできるものの、運用面での活用が進んでいない方
- 他システムとのデータ連携やバッチ処理の運用を担当している方
- 日々の運用業務や障害対応が属人化しており、改善したいと考えている方
なお、本記事ではワークフローエンジンや実行結果のメール通知など外部ツールは利用せず、Snowflake 単体で実現可能な範囲での運用改善を前提として一例を示します。
概要
取り扱う運用業務フロー
業務システムや外部サービスとの連携でよく見られる、以下のような定期バッチによるデータ連携フローを想定します。

運用上の課題
ファイル連携を前提とした定期バッチ処理では、各ステップが正しく実行されているかを運用担当者が個別に確認する必要があります。
そのため運用負荷が上がり、作業がクエリ実行やログ確認に依存しやすく、以下のような課題が発生します。
- データ受領時に、ファイル未着や内容不正にすぐ気付くことができない
- Snowflake 上の処理状況やチェック結果を都度クエリで確認する必要がある
- 他システムへの連携時に、連携内容の確認やリカバリ手順が標準化されていない
実装するアプリケーションの全体像
上記の課題を解消するため、運用業務を可視化・標準化するアプリケーションをSnowflake 単体で完結する構成で実装します。
本アプリケーションでは、運用担当者が都度クエリを書くことなく、画面上から以下のような状況確認や必要最低限の操作を行えるようにします。
- 各バッチ処理ステップの実行状況を一覧で確認できる
- データ受領状況や処理結果に関する情報(件数やステータスなど)を画面上で確認できる
- 異常が発生した場合に、対象となる処理やデータを特定しやすい
- 状況に応じたリカバリ操作を、あらかじめ定義した手順に沿って実行できる
実装詳細
Streamlitとは?
Streamlit は、Python コードのみで簡単に Web アプリケーションを構築できるオープンソースライブラリです。Snowflake ではこの Streamlit を標準機能として提供しており、 追加のインフラ構築や認証設定を行うことなく、Snowflake 上のデータを直接操作するアプリケーションを作成することができます。
本記事で取り扱う Streamlit のバージョンは、Streamlit version: 1.56.0 です。
アプリケーションの構成要素
実装するアプリケーションは、Snowflake 上で提供されている機能のみを用いて、以下の要素で構成しています。
- Streamlit アプリ
- 運用管理用テーブル
- ファイル連携用ステージ
- 既存のバッチ処理(タスクやプロシージャ)
なお本記事では、運用管理テーブルの状態をもとにした状況把握と実装の流れに焦点を当てるため、タスクやプロシージャを Streamlit アプリから呼び出す実装は避け、Pythonコード内に直接簡略化した処理を埋め込んでいます。
Streamlit アプリの画面構成
本アプリケーションでは、各バッチ処理ステップの最新の処理状況を可視化し、必要に応じて過去の処理状況の確認やリカバリ操作を行えるシンプルな画面構成とします。
運用担当者がクエリを書くことなくリカバリ要否を判断し、必要に応じた操作ができることを目指します。
実装①:最新の処理状況の可視化
まずは、各処理ステップの実行状況を可視化する画面を作成します。
以下のような運用管理テーブルを事前に準備しておきます。Streamlit はこちらのテーブルに整理された情報を参照するように設計します。
CREATE TABLE TECHBLOG_SANDBOX.OPERATE_APP.PROCESS_STATUS (
process_dt TIMESTAMP, -- 処理対象日時(例: 2026-04-01 00:00:00)
step_name STRING, -- RECEIVE / TRANSFORM / EXPORT
target_name STRING, -- SALES / ITEM_MASTER / ITEM_SUMMARY
status STRING, -- SUCCESS / ERROR / NOT_STARTED
in_count NUMBER, -- 入力件数
out_count NUMBER, -- 出力件数
message STRING, -- メッセージ(件数不一致など)
last_updated TIMESTAMP -- レコード更新日時
);
Streamlit の作成画面に遷移し、アプリタイトル、アプリの場所(データベースおよびスキーマ)、Python 実行環境、クエリウェアハウスを選択して作成します。 作成すると以下のような画面が立ち上がります。
作成すると以下のような画面が立ち上がります。
 streamlit_app.py のコードを以下のように記述します。運用管理テーブルから最新処理のレコードをわかりやすく表示するという内容です。
streamlit_app.py のコードを以下のように記述します。運用管理テーブルから最新処理のレコードをわかりやすく表示するという内容です。
import streamlit as st
import pandas as pd
from snowflake.snowpark.context import get_active_session
st.title("業務運用支援アプリケーション")
session = get_active_session()
# =========================
# 最新ステータス一覧
# =========================
latest_query = """
SELECT
process_dt,
step_name,
target_name,
status,
in_count,
out_count,
message
FROM (
SELECT
process_dt,
step_name,
target_name,
status,
in_count,
out_count,
message
ROW_NUMBER() OVER (
PARTITION BY step_name, target_name
ORDER BY process_dt DESC
) AS rn
FROM TECHBLOG_SANDBOX.OPERATE_APP.PROCESS_STATUS
)
WHERE rn = 1
ORDER BY process_dt
"""
latest_df = session.sql(latest_query).to_pandas()
latest_df.columns = [c.lower() for c in latest_df.columns]
# 件数を「整数」として扱う
latest_df["in_count"] = latest_df["in_count"].astype("Int64")
latest_df["out_count"] = latest_df["out_count"].astype("Int64")
# 件数差分チェック
latest_df["差分"] = latest_df["in_count"] != latest_df["out_count"]
# ステータスの色付け
def color_status(val):
if val == "ERROR":
return "color: red; font-weight: bold"
if val == "SUCCESS":
return "color: blue; font-weight: bold"
return ""
styled_latest_df = latest_df.style.applymap(
color_status,
subset=["status"]
)
st.subheader("最新の処理状況")
st.dataframe(
styled_latest_df,
hide_index=True,
column_config={
"差分": st.column_config.CheckboxColumn("Check"),
},
)
コードを記述し、右上の実行ボタンを押すと再実行されます。実行が完了すると以下のように処理状況がテーブル形式で表示されます。


実行ステータスをわかりやすく色付けし、入力件数と出力件数に差分がある際はCheckのカラムに表示してみました。Streamlit ではこのように表示を自由にカスタマイズできるため、実際の運用に合わせて調整可能です。
今回のケースでは、テーブル加工時にエラーが発生し、アンロード処理が実施されていないことがわかります。メッセージを確認すると、エラー原因はマスタの不備の可能性がありそうです。どのような件数変化があったのか
実装②:過去の処理履歴
次に、過去の処理履歴を可視化する画面を実装します。ステップ単位、出力テーブル単位で処理実行履歴と件数推移を表示できるようにします。
Pythonコードに以下を追記します。ステップとテーブルのセレクタ、選択したテーブルの実行履歴および件数推移の折れ線グラフを表示するという内容です。
# =========================
# 詳細確認用セレクタ
# =========================
st.subheader("過去の処理履歴")
step = st.selectbox(
"処理ステップ",
sorted(latest_df["step_name"].unique())
)
target = st.selectbox(
"対象",
sorted(
latest_df[
latest_df["step_name"] == step
]["target_name"].unique()
)
)
# =========================
# 履歴取得
# =========================
history_query = f"""
SELECT
process_dt,
status,
in_count,
out_count,
message
FROM TECHBLOG_SANDBOX.OPERATE_APP.PROCESS_STATUS
WHERE step_name = '{step}'
AND target_name = '{target}'
ORDER BY process_dt
"""
history_df = session.sql(history_query).to_pandas()
history_df.columns = [c.lower() for c in history_df.columns]
# 履歴側も整数型に揃える
history_df["in_count"] = history_df["in_count"].astype("Int64")
history_df["out_count"] = history_df["out_count"].astype("Int64")
st.subheader(f"{step} / {target} の実行履歴")
st.dataframe(history_df, hide_index=True)
# =========================
# 件数推移グラフ
# =========================
st.subheader("件数推移")
chart_df = history_df.set_index("process_dt")[["in_count", "out_count"]]
st.line_chart(chart_df)
再実行すると以下のような処理ステップと対象テーブルのセレクタ画面が追加されます。

選択すると、以下のように実行履歴と件数推移が表示されます。
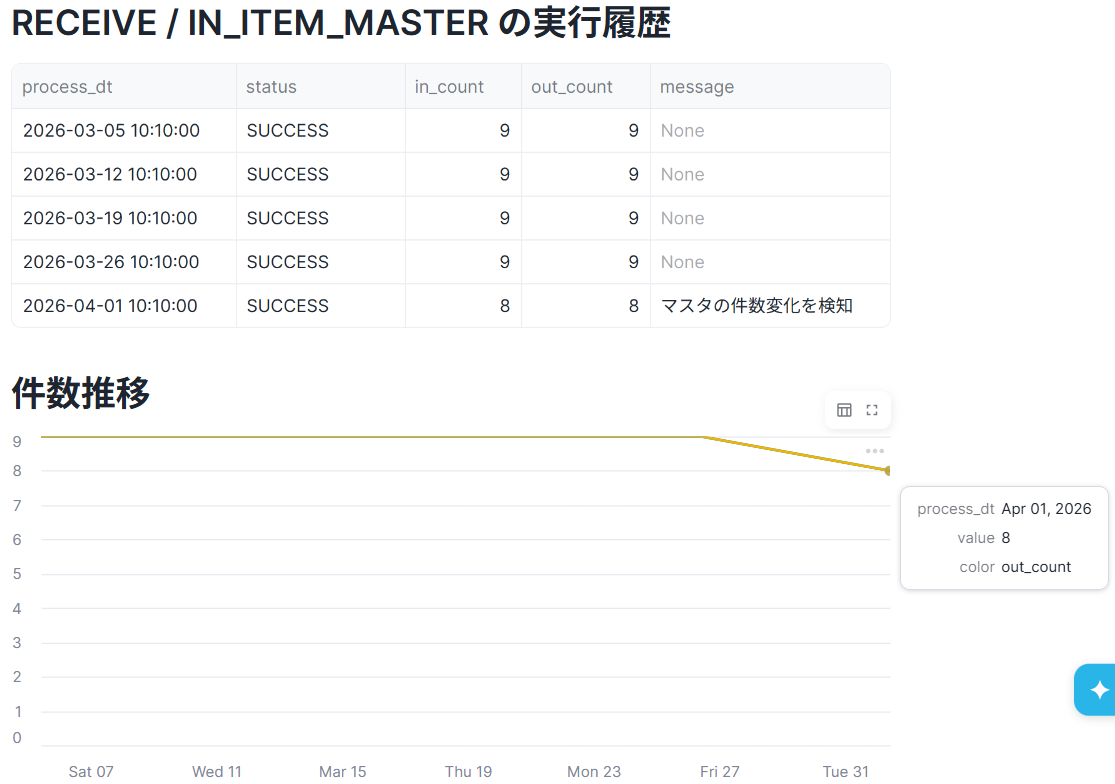
今回のケースでは、受領したマスタテーブルにレコード減少が発生していたことがわかりました。これが原因で加工プロセスで件数変化が生じたためにエラーが発生したようですね。原因がわかりましたので、次の画面でリカバリを実施しましょう。
実装③:リカバリ実行
最後に、クエリを毎回書かずにリカバリを実施することができる画面を実装します。処理単位で必要な部分だけを再実行できるようにします。
Pythonコードに以下を追記します。ロード処理の実行、加工処理の実行、アンロード処理の実行ボタンを表示するという内容です。
# =========================
# リカバリ操作
# =========================
st.subheader("リカバリ操作")
# EXPORT の最新ステータスで判定
export_row = latest_df[
(latest_df["step_name"] == "EXPORT") &
(latest_df["target_name"] == "OUT_ITEM_SUMMARY")
]
# EXPORT が未完了ならリカバリが必要
needs_recovery = (
export_row.empty or
export_row["status"].iloc[0] != "SUCCESS"
)
if needs_recovery:
current_status = (
"NOT_STARTED"
if export_row.empty
else export_row["status"].iloc[0]
)
st.info(
f"EXPORT のステータスは {current_status} です。"
"リカバリ操作が可能です。"
)
col1, col2 = st.columns(2)
col3, col4 = st.columns(2)
with col1:
reload_item_master = st.button("ITEM_MASTER 再ロード")
with col2:
reload_sales = st.button("SALES 再ロード")
with col3:
re_transform = st.button("加工処理 再実行")
with col4:
export_data = st.button("アンロード実行")
# -------------------------
# 押下時の処理(本ケース専用のダミー)
# -------------------------
if reload_item_master:
session.sql("""
INSERT INTO TECHBLOG_SANDBOX.OPERATE_APP.PROCESS_STATUS
VALUES (
'2026-04-01 13:15:00',
'RECEIVE',
'IN_ITEM_MASTER',
'SUCCESS',
9,
9,
'ITEM_MASTER を再連携',
CURRENT_TIMESTAMP
)
""").collect()
st.success("ITEM_MASTER を再ロードしました。")
if reload_sales:
session.sql("""
INSERT INTO TECHBLOG_SANDBOX.OPERATE_APP.PROCESS_STATUS
VALUES (
'2026-04-01 13:45:00',
'RECEIVE',
'IN_SALES',
'SUCCESS',
31,
31,
'SALES を再受領',
CURRENT_TIMESTAMP
)
""").collect()
st.success("SALES を再ロードしました。")
if re_transform:
session.sql("""
INSERT INTO TECHBLOG_SANDBOX.OPERATE_APP.PROCESS_STATUS
VALUES (
'2026-04-01 13:45:00',
'TRANSFORM',
'TMP_SALES',
'SUCCESS',
31,
31,
'マスタ再連携後に再実行',
CURRENT_TIMESTAMP
)
""").collect()
st.success("加工処理を再実行しました。")
if export_data:
session.sql("""
INSERT INTO TECHBLOG_SANDBOX.OPERATE_APP.PROCESS_STATUS
VALUES (
'2026-04-01 14:15:00',
'EXPORT',
'OUT_ITEM_SUMMARY',
'SUCCESS',
9,
9,
'リカバリ後にアンロード',
CURRENT_TIMESTAMP
)
""").collect()
st.success("アンロードを実行しました。")
else:
st.success("EXPORT 処理は正常に完了しています。")
再実行すると、以下のような画面が表示され、誤実行が発生しないようリカバリが必要な場合にのみ実行が可能となります。

今回のケースでは、ITEM_MASTERのロードに問題があったためエラーが発生していました。そのため、ITEM_MASTER再ロード⇒加工処理再実行⇒アンロード実行の流れでリカバリするのが適切です。



リカバリ操作完了後にデータを更新すると、最新の処理状況の STATUS がすべて SUCCESS となっていることが確認できます。

この状態では、以下のように正常処理表示となりリカバリボタンは表示されません。

まとめ
本記事では、Snowflake を基盤としたデータ分析環境において、日々の運用業務を「クエリを実行して確認する作業」から「画面を見て判断・操作する作業」へと置き換え、運用負荷の削減や属人化の防止に対応する一例をご紹介しました。
今回の実装は最小構成ではありますが、Snowflake の標準機能のみを用いているため多くの初学者にとって手を伸ばしやすい内容となっております。
Streamlit の他にも Snowflake には数多くの機能があり、適切に活用することができれば既存業務が抱えていた課題に対してアプローチすることが可能だと考えます。
今後の Snowflake 活用を推進するための一例として、本記事の内容が参考になれば幸いです。
参考文献
[1] Streamlit in Snowflake について | Snowflake Documentation
[2] Streamlit documentation
[3] pandas documentation — pandas 3.0.2 documentation
